
El análisis de vídeo basado en IA se usa ampliamente en industrias de seguridad y vigilancia, alimentos y bebidas, comercio minorista, transporte y fabricación y logística, solo por nombrar algunas. Es un mercado que se espera que tenga una alta tasa de crecimiento en los próximos años junto con la amplia difusión de la tecnología Edge-AI.
¿Qué es el análisis de vídeo basado en IA?
El análisis de vídeo basado en IA, también conocido como análisis de contenido de vídeo (VCA, por sus siglas en inglés, Video Content Analysis), IA de vídeo o vídeo inteligente, se refiere al proceso de obtener información y conclusiones procesables a partir de los datos recopilados en forma de vídeo digital.
El análisis de vídeo basado en IA simplifica y alivia la carga de las tareas repetitivas y tediosas de la observación de vídeo durante horas por parte de humanos. La IA no solo puede observar datos, sino que también puede entrenarse con grandes volúmenes de secuencias de vídeo para detectar, identificar, categorizar y etiquetar automáticamente objetos específicos.
En general, es una herramienta utilizada para ayudar a las personas a comprender el contenido del vídeo y tomar decisiones automatizadas basadas en las observaciones realizadas a partir de los datos recopilados.
Componentes clave de los sistemas de videovigilancia basados en IA
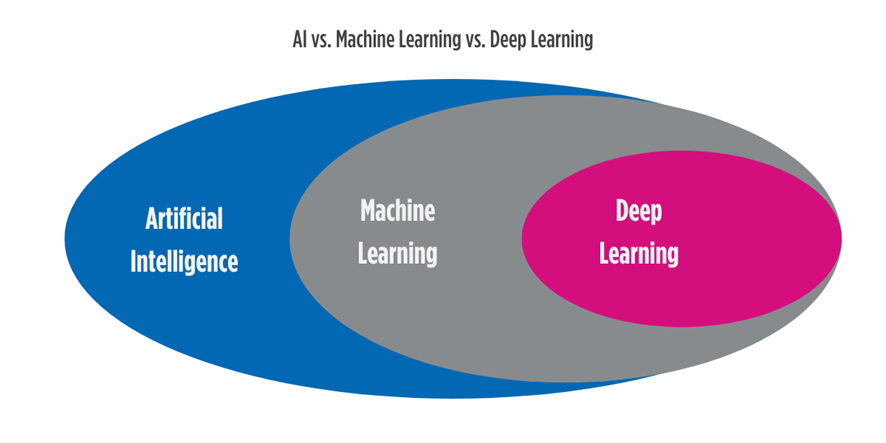
Para comprender completamente AI-Video Analytics, debemos tener en cuenta que el proceso combina dos tipos de IA, que son Machine Learning y Deep Learning. Pero antes de eso, definamos brevemente la IA.
Inteligencia artificial, aprendizaje automático y aprendizaje profundo
Inteligencia Artificial
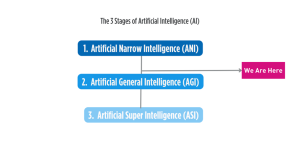
IA significa Inteligencia Artificial y es un campo que utiliza la informática y los datos para la resolución de problemas en las máquinas. John McCarthy, también conocido como uno de los padres fundadores de la inteligencia artificial, definió la IA en 1955 como “la ciencia y la ingeniería para fabricar máquinas inteligentes”. La IA es un tema amplio y puede ser abrumador aprender de un vistazo, por lo que comenzaremos con las tres etapas de la IA.
La IA tiene múltiples etapas, que se pueden dividir en tres etapas:
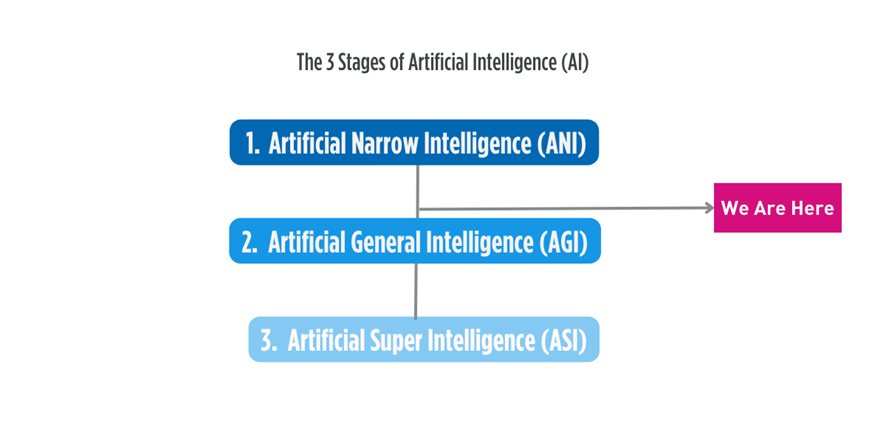
La primera es la Artificial Narrow Intelligence (ANI), donde un ordenador puede ejecutar un conjunto simple de tareas definidas, y solo esas tareas. La mayoría de las herramientas impulsadas por IA que tenemos a nuestra disposición hasta el día de hoy pertenecen a esta categoría. Por ejemplo, reconocimiento de voz o facial.
Luego, la Artificial General Intelligence (AGI), en esta etapa se supone que la IA es capaz de tomar decisiones y pensar de manera independiente, al igual que los humanos. Se cree que esta etapa se acerca rápidamente a medida que somos testigos de rápidos avances en los chatbots sociales como ChatGPT, capaces de razonamiento contextual y resolución de problemas. Esta etapa es más avanzada que ANI y es comparable a la inteligencia humana. Una forma de determinar si los robots han alcanzado o no el mismo nivel de inteligencia que los humanos es mediante la ejecución del Test de Turing de Alan Turing (1950).
Finalmente, está la Artificial Super Intelligence (ASI), donde la IA aprovecha la inteligencia que supera exponencialmente el nivel de inteligencia de un humano por magnitudes, que también se predice que será la singularidad tecnológica o «La Singularidad», donde el crecimiento de la IA se vuelve incontrolable e irreversible, causando un impacto imprevisible en la civilización humana.
Aprendizaje automático y aprendizaje profundo
Hay múltiples subconjuntos de IA y subconjuntos dentro de esos subconjuntos, pero los dos requeridos por Vídeo-IA son el aprendizaje automático (Machine Learning) y el aprendizaje profundo (Deep Learning). Los dos términos son campos relacionados dentro del dominio más amplio de la IA.
¿Alguna vez te has preguntado cómo se selecciona la pestaña «Programas elegidos para usted» en Netflix?
Quizás notaste que las películas en tu feed después de terminar una película reciente presentaban actores/actrices similares y pertenecían a los mismos géneros. O cuando la reproducción automática en YouTube crea una lista de reproducción de tu música favorita. Estos son ejemplos cotidianos de Machine Learning en acción.
El aprendizaje automático es un subconjunto de la inteligencia artificial, donde los algoritmos se utilizan para analizar datos, aprender de la información que se ha recopilado y luego aplicar este conocimiento para basar decisiones futuras con una interferencia humana mínima o nula.
Aunque Machine Learning puede convertirse de forma independiente en un experto en funciones específicas, requiere que los humanos dirijan y guíen las decisiones tomadas al decidir el resultado y requiere intervención cuando no devuelve la retroalimentación precisa o deseada. Este proceso se conoce como aprendizaje supervisado.
Entonces, en lugar de que un ser humano codifique cada decisión que puede tomar un ordenador, en cambio, un ordenador está «entrenado» recopilando, procesando y aprendiendo de los datos y luego tomando decisiones por su cuenta.
El aprendizaje profundo, por otro lado, es un subconjunto del aprendizaje automático y utiliza «redes neuronales» artificiales para imitar los procesos de aprendizaje de un cerebro humano. El aprendizaje profundo imita la forma en que los cerebros humanos procesan la información de forma no lineal.
Estas redes neuronales artificiales se componen de un concepto llamado capas de algoritmos y unidades de cómputo, que conforman las neuronas artificiales. Estas neuronas son la columna vertebral de los algoritmos de aprendizaje profundo. Una forma de diferenciar entre el aprendizaje automático y el aprendizaje profundo es observar la cantidad de capas de datos que debe procesar un ordenador. Si se trata de más de tres capas de procesamiento (incluidas la entrada y la salida), se considera Deep Learning.
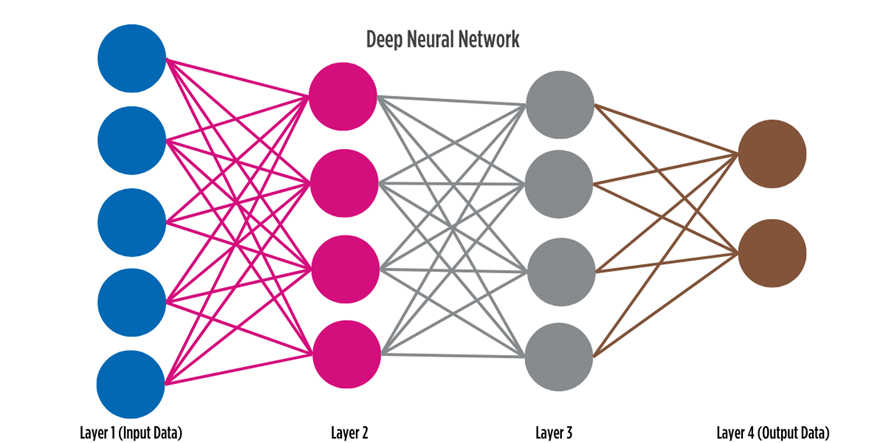
Donde Machine Learning puede convertirse en un experto en una función específica a través del aprendizaje y el análisis de datos preclasificados, Deep Learning aprende de forma independiente a través de la absorción de conjuntos de datos mucho más grandes, cada vez más diversos y no estructurados en su forma sin procesar, incluidas fotos, textos y números. A través de grandes volúmenes continuos de entrada de datos, los algoritmos de aprendizaje profundo pueden aprender observando patrones que ocurren en los grupos de datos que recopilan.
Deep Learning no depende de la extracción de funciones como lo hace Machine Learning, donde se especifica el proceso de selección cuidadosa de funciones relevantes por parte de expertos. El aprendizaje profundo puede aprender y extraer automáticamente características directamente de los datos sin procesar, lo que elimina la necesidad de ingeniería “manual”. Las redes neuronales profundas están diseñadas para aprender representaciones jerárquicas de los datos, capturando automáticamente patrones y características útiles en diferentes niveles de abstracción.
Podríamos decir que el aprendizaje profundo es una versión más avanzada y desarrollada de Machine Learning, donde puede manejar conjuntos de datos más complejos y proporcionar resultados que no requieren la intervención de humanos. Al eliminar la necesidad de que ingenieros codifiquen y categoricen explícitamente los conjuntos de datos, el procesamiento de datos se vuelve mucho más rápido y eficiente.
¿Cómo funciona el análisis de vídeo basado en IA? Ahora que hemos cubierto los conceptos básicos, pasemos al «cómo» y los métodos que utiliza el análisis de vídeo basado en IA, que es una tecnología llamada «Reconocimiento de objetos». El reconocimiento de objetos utiliza el aprendizaje profundo y cae dentro del campo de la visión artificial, una rama de la informática que estudia cómo los ordenadores pueden «ver».
Reconocimiento de objetos
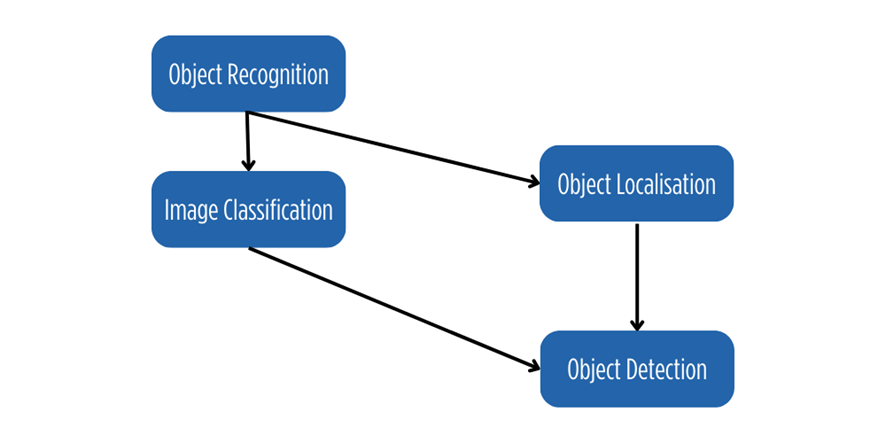
El reconocimiento de objetos (Object Recognition) se refiere a una colección de tareas relacionadas para identificar objetos en fotografías digitales.
La primera tarea es la clasificación de imágenes (Image Classification), donde se predice una clase para un objeto en una imagen.
La segunda tarea se denomina localización de objetos (Object Localisation), donde la ubicación de los objetos en una imagen se identifica con un cuadro delimitador y una etiqueta de clase.
Luego, la detección de objetos (Object Detection) combina estas dos tareas, clasificando y localizando los objetos detectados en una imagen. Cuando los usuarios usan el término «Reconocimiento de objetos», a menudo se refieren a Detección de objetos. La detección de objetos es un subconjunto del reconocimiento de objetos.
¿Por qué usar análisis de vídeo basados en IA?
El análisis de vídeo basado en IA brinda muchos beneficios a las empresas, que incluyen:
- Mejora de las medidas de seguridad y protección
- Optimización de la eficiencia operativa
- Garantizar la seguridad y la salud de los trabajadores
- Investigación y análisis de incidentes
¿Por qué utilizar análisis de vídeo basados en IA en el Edge?
Con las mayores capacidades de rendimiento de los dispositivos integrados, se procesan más datos en los lugares donde se recopilan, como sensores y sistemas embedded. El análisis de vídeo basado en IA también se ejecuta en el Edge en lugar de en la nube por razones como las siguientes:
- Latencia reducida. Cuando el vídeo basado en IA se ejecuta en el Edge, se minimiza el tiempo requerido para recibir una respuesta, ya que no es necesario enviar los datos de un lado a otro desde la nube. Esto marca una diferencia drástica en situaciones en las que se deben tomar acciones en tiempo real y mejora significativamente las condiciones en términos de seguridad y vigilancia, a menudo la razón por la cual se implementa el vídeo basado en IA en primer lugar.
- Mayor privacidad y seguridad. Hay una vulnerabilidad reducida ya que el análisis ocurre justo donde se recopilan los datos y no se utiliza Internet, donde los datos pueden ser pirateados. Este es un beneficio adicional cuando se analizan datos que almacenan información de identificación personal, como datos de reconocimiento facial.
- Eficiencia de ancho de banda. Las empresas pueden beneficiarse de la eficiencia del ancho de banda de la computación en el borde, ya que solo los datos necesarios que requieren un procesamiento adicional se envían a la nube. Esto libera más capacidad de ancho de banda y reduce los costes de transferencia de datos y el consumo de energía.
- Operación fuera de línea. El procesamiento de vídeo basado en IA en el borde puede ocurrir incluso sin conexión a Internet. Esto es particularmente ventajoso en áreas donde la conectividad continua puede verse interrumpida o, a veces, no estar disponible en ubicaciones remotas.
- Toma de decisiones en tiempo real. Un propósito atractivo para utilizar el análisis de vídeo basado en IA en el borde es la capacidad de los ordenadores para calcular y llevar a cabo de forma independiente decisiones de misión crítica que pueden tener consecuencias nefastas si se espera que se lleven a cabo más análisis en el nivel de la nube.
- Escalabilidad mejorada. Cuando el Vídeo-IA se analiza en los propios sensores, esto mejora y deja espacio para la escalabilidad, ya que permite que más dispositivos lleven la carga del procesamiento y análisis de datos. Habilitar la ejecución de tareas en paralelo en varios dispositivos perimetrales facilita la carga y distribuye las tareas de manera eficiente.
¿Qué necesitan los sistemas informáticos industriales para ejecutar Vídeo IA?
A menudo, los ordenadore encargados de aplicaciones de análisis de vídeo basadas en IA se colocan en entornos hostiles desfavorables, que incluyen terrenos remotos donde hay altos niveles de polvo y partículas en el aire, terrenos inestables o en movimiento cerca de otros objetos en movimiento cercanos, o entornos al aire libre con oscilación de temperaturas y cambios drásticos en el clima, e incluso la exposición a altos niveles de humedad o aerosoles. Estas condiciones ejercen una presión adicional sobre estos sistemas además de los requisitos de compatibilidad de software para los niveles continuos y exigentes de procesamiento de datos involucrados en el Vídeo-IA.
Aceleradores de hardware para análisis de vídeo basados en IA
Las duras condiciones en el borde exigen sistemas que puedan operar de manera confiable las 24 horas del día, los 7 días de la semana, sin interrupciones, mientras llevan a cabo funciones de misión crítica, como los ordenadores industriales robustos y sin ventilador.
Hay requisitos de hardware específicos que se deben tener en cuenta para obtener un rendimiento óptimo y resultados satisfactorios al utilizar el análisis de vídeo basado en IA en sus aplicaciones industriales.
En primer lugar, un procesador potente es esencial para manejar los cálculos complejos involucrados en los algoritmos de IA. Los sistemas informáticos industriales que se utilizan para el análisis de vídeo basado en IA generalmente incluyen GPU (unidad de procesamiento gráfico) para capacidades avanzadas de procesamiento de imágenes.
Aceleradores de IA dedicados tipo ASIC (Aplication Specific Integrated Circuit) como las TPU (Tensor Processing Unit) de Google y HAILO aceleran las aplicaciones integradas de aprendizaje profundo en dispositivos perimetrales. Los FPGA (Field Programmable Gate Array) también se usan comúnmente para un procesamiento paralelo eficiente.
Luego, se necesita una amplia memoria, tanto RAM como de almacenamiento, para almacenar y acceder a grandes cantidades de datos de manera eficiente. Las soluciones de almacenamiento de alta velocidad, como las SSD NVMe (unidades de estado sólido Express de memoria no volátil), facilitan la recuperación rápida de datos.
Por último, la compatibilidad con los modelos de lenguaje de IA y los marcos de software garantizan una integración y utilización fluidas de las capacidades de IA.
Ordenadores industriales reforzados para análisis de vídeo basados en IA Con un diseño modular, apilable y de dos piezas, el PC industrial robusto y sin ventilador con SSD NVME hot-swap, de la serie RCO-3000 y 6000 permite la detección de objetos y análisis de vídeo AI de alta potencia mientras genera una salida de pantalla en real tiempo. Este BoxPC incluye funciones de seguridad integradas, lo que hace que las actualizaciones y reparaciones sean fácilmente accesibles para los operadores sin necesidad de reemplazar un sistema completo. La serie RCO es una solución competitiva para tareas de visión artificial en cualquier entorno industrial hostil.















